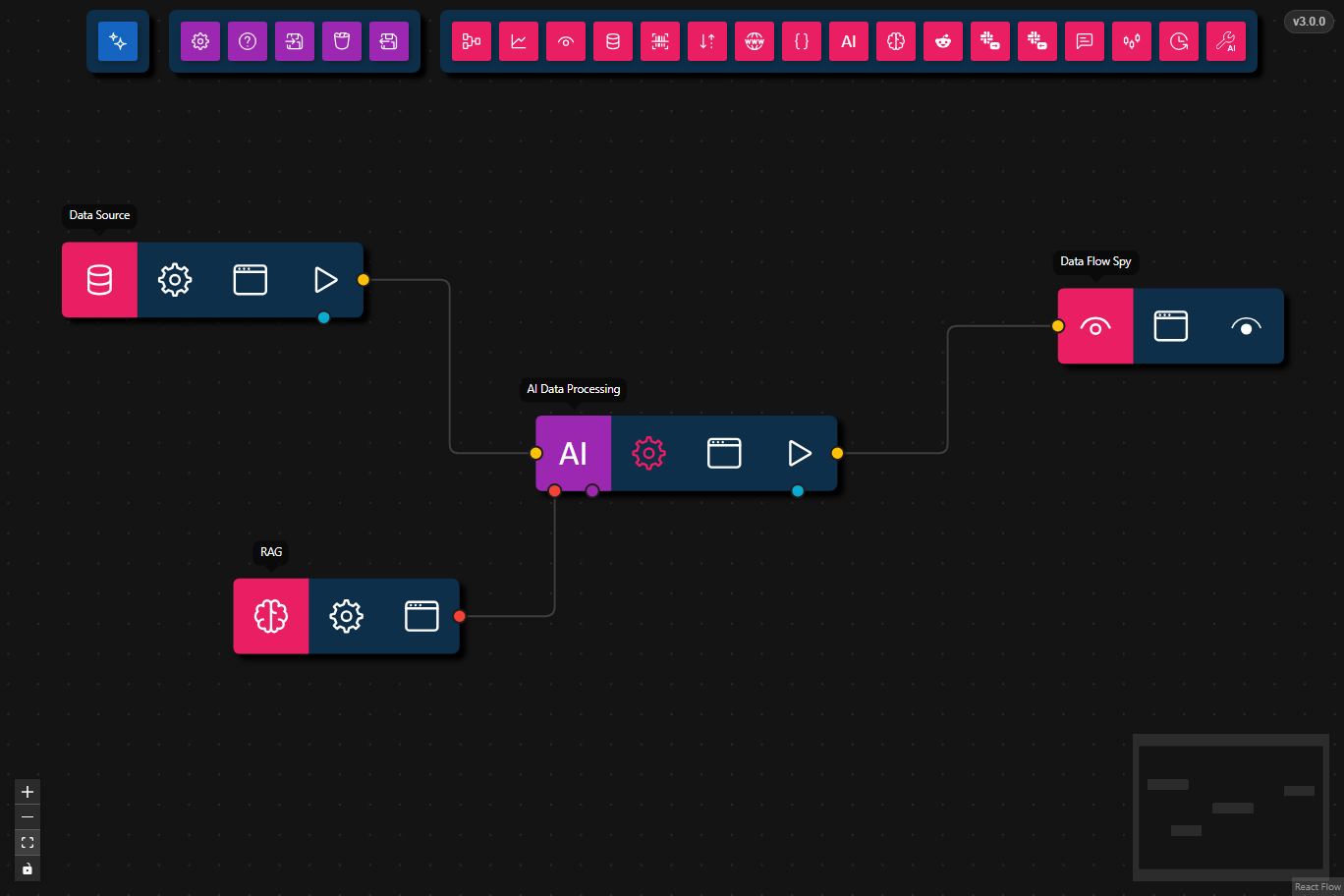
RAG Eval Workflow
This workflow demonstrates Retrieval-Augmented Generation in Agentic Signal by ingesting a text document into a RAG collection, retrieving the most relevant passages, and generating an answer from the retrieved evidence.
- Preview
- JSON
- Node Configuration
{
"nodes": [
{
"id": "56ad3656-73e7-4e95-b84c-bd3b96453be3",
"type": "data-source",
"data": {
"title": "Data Source",
"dataSource": {
"value": {
"text": "Using rag_test_large_document.txt, answer:\r\n\r\nWhat are the main benefits of a hybrid retrieval architecture versus a pure semantic retriever?\r\nHow does metadata filtering improve retrieval relevance in mixed-domain corpora?\r\nWhy did the enterprise knowledge search case study find versioned metadata important?",
"files": [
{
"name": "rag_test_large_document.txt",
"content": "```text\nThe Comprehensive Guide to Retrieval-Augmented Generation\r\n=======================================================\r\n\r\nIntroduction\r\n------------\r\nThis document is a comprehensive reference guide for designing, deploying, and evaluating retrieval-augmented generation systems. It explains core architecture patterns, content preparation, retrieval strategies, model prompting, and operational best practices.\r\n\r\nThe guide has been written to contain a very large amount of text so that retrieval can be tested against a document larger than the typical 4000-token context window. The goal is to ensure the RAG pipeline loads only the relevant portions and not the entire file when a query is issued.\r\n\r\nDistributed AI systems are challenging because they require integration across storage, retrieval, indexing, and generation. Each section in this document focuses on one part of the pipeline and explains how the pieces interact in real deployments.\r\n\r\nArchitecture Overview\r\n---------------------\r\nA retrieval-augmented generation architecture typically consists of three main components: a document repository, a retriever, and a generator. The document repository stores raw source content, the retriever matches queries to candidate passages, and the generator synthesizes answers from those passages.\r\n\r\nIn many architectures, the document repository is split into two stores: an object store for raw text and a vector store for embeddings. Metadata is usually kept in a separate database or search index to allow structured filtering on attributes like document type, author, or date.\r\n\r\nThe retriever is often implemented as a hybrid search system. It can combine exact keyword matching with dense vector similarity. The hybrid approach helps preserve precision while also capturing semantic meaning when user queries are phrased in natural language.\r\n\r\nSelecting the right retriever configuration depends on the expected query patterns. If users are asking for policy details or product instructions, the system should optimize for high recall on procedural information. If users are asking for definitions or summaries, semantic similarity often works better.\r\n\r\nDocument Preparation\r\n--------------------\r\nDocuments must be prepared before ingestion. Preparation includes normalization, chunking, metadata extraction, and quality checks. Normalization standardizes whitespace, encoding, and punctuation across the corpus.\r\n\r\nChunking is one of the most important decisions in a RAG system. If chunks are too large, the model ingest stage will include excessive irrelevant context and increase latency. If chunks are too small, the retriever may fail to return enough useful information. Common chunk sizes are between 200 and 400 words, depending on the domain.\r\n\r\nMaintaining section boundaries is helpful. When dealing with highly structured content, such as manuals or compliance guides, preserving headings and subheadings in the chunk metadata makes it easier to rank relevant passages. The document preparation pipeline should annotate each chunk with the source section title.\r\n\r\nEmbeddings and Indexing\r\n-----------------------\r\nEmbeddings convert text into vectors. Different embedding models produce different vector spaces, and the choice of model impacts retrieval quality. For general knowledge, medium-sized embeddings are often enough. For technical or domain-specific language, it may be necessary to use specialized embeddings.\r\n\r\nIndexing strategies vary by scale. For small datasets, a flat index may suffice. For larger datasets, approximate nearest neighbor indexes such as HNSW, IVF, or PQ are preferred. These indexes provide much faster retrieval at the cost of a small amount of recall loss.\r\n\r\nIndex maintenance is critical. Documents are not static in most enterprise systems. The index should support additions, deletions, and updates without requiring a full rebuild. A practical pattern is to assign each chunk a stable document identifier and re-embed only changed chunks.\r\n\r\nIt is also beneficial to store metadata alongside embeddings. Metadata filters can pre-select candidates before the vector search stage. For example, filtering by document category, source system, or language will reduce noise and improve retrieval relevance.\r\n\r\nQuery Processing\r\n----------------\r\nWhen a user query arrives, it is first normalized and then embedded. The embedded query is used to retrieve top candidate passages from the vector index. The system may also use exact keyword matching as a fallback if the semantic retriever returns low-confidence results.\r\n\r\nThe retrieved candidate passages are usually rank-ordered by similarity score. A typical RAG system retrieves between 5 and 15 passages, then trims them to fit within the model context window. This trimming step must preserve the highest-value evidence.\r\n\r\nSome systems perform query rewriting or expansion. Query rewriting converts ill-formed or ambiguous queries into a more explicit form. Query expansion can add related terms and synonyms to improve recall when the original query is short.\r\n\r\nWhen metadata filters are available, the retrieval stage should apply them before the ranked list is assembled. This is especially important in mixed-domain corpora where different document types should not be mixed in a single answer.\r\n\r\nTruthfulness and Prompt Design\r\n-----------------------------\r\nPrompt design matters for RAG systems. The prompt should explicitly tell the model to use only the retrieved citations and not invent facts. A strong prompt can force a model to answer with evidence from the passages.\r\n\r\nA typical prompt includes a context section containing the retrieved passages, a question section with the user query, and an output instruction section that frames the response style. For example, the prompt may instruct the model to answer in bullet points, to cite paragraph numbers, or to say \"I do not know\" when the evidence is insufficient.\r\n\r\nThe prompt should also include an explicit rule to ignore unrelated content. Because retrieved passages often include extra context, the model must learn to extract only the relevant lines. Prompts that say \"Use only the following paragraphs to answer the question\" help reduce hallucination.\r\n\r\nIt is useful to store the exact prompt contents for each query. This allows engineers to reproduce responses and debug retrieval failures. Prompt logging is part of the overall observability strategy.\r\n\r\nMetrics and Monitoring\r\n----------------------\r\nEvaluation metrics for RAG systems include retrieval recall, answer accuracy, and user satisfaction. Retrieval recall measures whether the relevant passages appear in the candidate set. Answer accuracy measures whether the generated response is correct based on ground truth.\r\n\r\nOperational monitoring should include latency, error rates, and quality drift. Latency should be measured end-to-end, including retrieval and generation. Quality drift can be detected by monitoring model confidence signals, user feedback, and periodic human evaluation.\r\n\r\nMore advanced systems also track evidence usage. If certain retrieved passages are top-ranked but rarely cited in the final answer, that may indicate a mismatch between retrieval and generation. Tracking evidence usage helps tune the reranker or the prompt.\r\n\r\nCase Study: Enterprise Knowledge Search\r\n--------------------------------------\r\nThis case study describes a large enterprise knowledge search system. The corpus included policies, internal procedures, product manuals, and training guides. The system was deployed to support employees across multiple business units.\r\n\r\nThe retrieval pipeline combined exact matching on policy numbers with semantic embeddings for natural language questions. Metadata tags for business unit, document type, and update date were used to filter results before ranking.\r\n\r\nThe system reduced time to answer by 30% for support personnel. It also improved compliance because employees were more likely to surface the latest procedures. Continuous monitoring showed that the hybrid retriever maintained a high recall rate even as the corpus grew.\r\n\r\nA specific implementation lesson from this case study is the value of versioned metadata. Documents were tagged with version history and effective date, which allowed the retriever to preferentially return the most current guidelines.\r\n\r\nCase Study: Support Summaries\r\n-----------------------------\r\nThis case study covers an AI system built to summarize customer support interactions. The data included long ticket histories, conversation logs, and product notes. The RAG system extracted relevant dialogue snippets and generated incident summaries.\r\n\r\nThe retrieval engine was tuned to prioritize the most recent interactions while still preserving key historical context. The system used a sliding window over the last 25 support exchanges and ranked them by semantic similarity to the current customer issue.\r\n\r\nThe generated summaries were presented to support agents as draft responses. Agents could validate the summary against the cited passages and make corrections. This approach maintained quality while significantly reducing the time needed to understand a complex ticket.\r\n\r\nA critical operational note from this deployment is that evidence citations must remain visible. Agents trusted the summary more when they could see which passages the system used, and they were less likely to discard the answer entirely.\r\n\r\nAppendix: Implementation Patterns\r\n--------------------------------\r\nThis appendix lists implementation patterns for distributed AI systems. The patterns emphasize modularity, observability, and data quality.\r\n\r\nPattern 1: Separate retrieval from generation. The retrieval service should be independent from the model-serving layer. This makes it easier to scale each component separately and to swap embedding models or vector indexes without touching the generator.\r\n\r\nPattern 2: Use metadata filters upstream. Applying metadata filters before vector search reduces noise and improves relevance. Filters may include document type, language, author, and publication date.\r\n\r\nPattern 3: Store trace logs for every query. Log the user query, the retrieved passages, the prompt, and the final response. These logs are essential for debugging hallucinations and measuring end-to-end quality.\r\n\r\nPattern 4: Use stable identifiers for text chunks. Stable identifiers allow partial reindexing when documents change. They also make it easier to track citations back to the original source.\r\n\r\nPattern 5: Maintain human-in-the-loop evaluation. Periodic human review of generated answers catches errors that automatic metrics miss. Human feedback is especially important for factual accuracy and answer usefulness.\r\n\r\nPattern 6: Prefer a hybrid retriever in mixed-domain corpora. When the corpus contains technical manuals, policies, and conversational logs, a hybrid retriever can balance precision and semantic recall.\r\n\r\nPattern 7: Keep prompt templates in version control. Treat prompt design as code. Store prompt templates alongside system configuration so you can reproduce answers and roll back changes.\r\n\r\nPattern 8: Implement a fallback response strategy. If the retrieved evidence is weak or the generated answer is uncertain, the system should respond with a safe fallback such as \"I cannot answer that accurately with the available information.\" This avoids harmful hallucinations.\r\n\r\nPattern 9: Use incremental indexing for updates. When documents change, index only the updated chunks instead of rebuilding the entire corpus. This reduces downtime and keeps retrieval current.\r\n\r\nPattern 10: Log quality drift signals. Track changes in the retrieval score distribution, user satisfaction, and query volume. Unexpected drift often indicates a need to refresh embeddings or retrain ranking models.\r\n\r\nPattern 11: Keep content chunk sizes consistent. Consistency in chunk size improves retrieval quality because the vector index learns from similarly sized passages. Aim for average chunk lengths that fit the target model’s context window.\r\n\r\nPattern 12: Provide a query explanation layer. When returning an answer, include a brief explanation of why the selected passages were chosen. This builds user trust and helps operators diagnose relevance problems.\r\n\r\nPattern 13: Use cached results for frequent queries. Popular questions can be cached at the answer level or at the retrieved passage level, reducing repeated retrieval and generation costs.\r\n\r\nPattern 14: Monitor connector failures. If the document ingestion connector fails, the corpus can become stale. Alert on connector downtime and ingestion pipeline errors.\r\n\r\nPattern 15: Separate training corpora from production corpora. Training data often includes annotations and private examples. Keep it distinct from the live retrieval corpus to avoid leakage and compliance issues.\r\n\r\nPattern 16: Include a human review step for high-risk outputs. For answers that involve legal, safety, or compliance content, require human review before delivery.\r\n\r\nPattern 17: Enable document-level access control. Attach access metadata to documents and enforce it in the retrieval layer. This prevents confidential content from being returned to unauthorized users.\r\n\r\nPattern 18: Use a multi-stage retrieval cascade. A fast lightweight retriever can produce a candidate set that is then re-ranked by a more accurate but expensive model. This balances speed and precision.\r\n\r\nPattern 19: Evaluate with both open-ended and closed-ended tasks. Open-ended tasks measure usefulness, while closed-ended tasks such as exact-match queries measure factual accuracy.\r\n\r\nPattern 20: Keep a glossary of domain terms. When the document corpus contains specialized vocabulary, a glossary helps the retriever and the model understand technical terms consistently.\r\n\r\nPattern 21: Use schema-based metadata when available. Schema-based metadata makes it easier to query by specific fields such as product name, region, or release version.\r\n\r\nPattern 22: Annotate sensitive content explicitly. Mark paragraphs that contain personally identifiable information or regulated data so that the retriever can exclude them when necessary.\r\n\r\nPattern 23: Maintain a fallback data source. If the primary corpus becomes unavailable, the system should gracefully degrade to a secondary source or provide a safe no-answer response.\r\n\r\nPattern 24: Balance retrieval set size and context length. More candidate passages increase coverage but also increase the risk of exceeding the model context window. Use a fixed budget of tokens for the reader stage.\r\n\r\nPattern 25: Use post-generation validation. After the model generates an answer, validate the response against the retrieved evidence. If the response contradicts the evidence, flag it for review or regeneration.\r\n\r\nPattern 26: Keep prompts short and specific. Long prompts can increase latency and cost. Use focused prompts that emphasize the exact task and the relevant evidence.\r\n\r\nPattern 27: Track user feedback explicitly. Record thumbs-up, thumbs-down, and correction notes. Use this feedback to retrain ranking and generation policies.\r\n\r\nPattern 28: Include source references in the final answer. When possible, cite the source document titles, sections, or chunk identifiers that support the response.\r\n\r\nPattern 29: Handle ambiguous queries by asking clarifying questions. If the query is too broad, generate a follow-up question instead of guessing the user intent.\r\n\r\nPattern 30: Use a human-readable evidence format. Present retrieved passages in a consistent format that engineers and reviewers can easily understand during debugging.\r\n\r\nPattern 31: Maintain a list of unsupported query types. For queries that require real-time data or confidential content, explicitly return a denial message rather than hallucinating.\r\n\r\nPattern 32: Segment very long documents by logical sections. Large manuals and reports should be split by subsections so the retriever can return narrowly relevant segments.\r\n\r\nPattern 33: Use explicit quoting when summarizing. When the answer is based on a passage, include a quoted excerpt to preserve fidelity.\r\n\r\nPattern 34: Keep the embedding model and the generation model aligned. If the embedding model changes significantly, re-evaluate retrieval quality against known queries.\r\n\r\nPattern 35: Audit model output regularly. Periodic audits of generated responses catch drift and emerging hallucination modes.\r\n\r\nPattern 36: Use caching for repeated prompt templates. If the system uses many similar prompts, template caching reduces runtime overhead.\r\n\r\nPattern 37: Provide operator controls for retrieval thresholds. Allow tuning similarity thresholds and candidate set sizes without redeploying code.\r\n\r\nPattern 38: Document the retrieval pipeline clearly. Keep architecture diagrams, component responsibilities, and data flow descriptions in project documentation.\r\n\r\nPattern 39: Manage embeddings lifecycle. Track when embeddings were created and schedule refreshes for content that changes frequently.\r\n\r\nPattern 40: Prioritize user intent. Always design the retrieval pipeline around what users are trying to accomplish, not just what documents are available.\r\n\n```"
}
]
},
"type": "markdown"
}
},
"position": {
"x": 436.5,
"y": 173.5
},
"measured": {
"width": 160,
"height": 40
},
"selected": false
},
{
"id": "47efbe40-026d-4c73-9d18-17faad0e501f",
"type": "data-flow-spy",
"data": {
"title": "Data Flow Spy"
},
"position": {
"x": 965,
"y": 198
},
"measured": {
"width": 120,
"height": 40
},
"selected": false
},
{
"id": "bac87483-9350-45d8-92cd-1b4d6ec2db23",
"type": "llm-process",
"data": {
"title": "AI Data Processing",
"model": "",
"prompt": "",
"format": {},
"maxFeedbackLoops": 0,
"maxToolRetries": 3
},
"position": {
"x": 688,
"y": 265.5
},
"measured": {
"width": 160,
"height": 40
},
"selected": true
},
{
"id": "b574a299-1fdc-4658-8150-b0d3160dab36",
"type": "rag",
"data": {
"title": "RAG",
"embeddingModel": "nomic-embed-text:latest",
"collectionName": "test_collection",
"chunkSize": 64,
"chunkOverlap": 16,
"topK": 5,
"weaviateUrl": "http://localhost:8080",
"weaviateApiKey": ""
},
"position": {
"x": 527.5,
"y": 352
},
"measured": {
"width": 120,
"height": 40
},
"selected": false,
"dragging": false
}
],
"edges": [
{
"source": "56ad3656-73e7-4e95-b84c-bd3b96453be3",
"target": "bac87483-9350-45d8-92cd-1b4d6ec2db23",
"type": "smoothstep",
"animated": false,
"sourceHandle": "flow",
"targetHandle": "flow",
"id": "xy-edge__56ad3656-73e7-4e95-b84c-bd3b96453be3right-source-bac87483-9350-45d8-92cd-1b4d6ec2db23left-target"
},
{
"source": "bac87483-9350-45d8-92cd-1b4d6ec2db23",
"target": "47efbe40-026d-4c73-9d18-17faad0e501f",
"type": "smoothstep",
"animated": false,
"sourceHandle": "flow",
"targetHandle": "flow",
"id": "xy-edge__bac87483-9350-45d8-92cd-1b4d6ec2db23right-source-47efbe40-026d-4c73-9d18-17faad0e501fleft-target"
},
{
"source": "b574a299-1fdc-4658-8150-b0d3160dab36",
"target": "bac87483-9350-45d8-92cd-1b4d6ec2db23",
"type": "smoothstep",
"animated": false,
"sourceHandle": "context",
"targetHandle": "context",
"id": "xy-edge__b574a299-1fdc-4658-8150-b0d3160dab36rag-target-bac87483-9350-45d8-92cd-1b4d6ec2db23rag-target"
}
]
}
- Data Source
- Input: query prompt plus the attached
rag_test_large_document.txtfile
- Input: query prompt plus the attached
- RAG
- Embedding Model:
nomic-embed-text:latest - Collection:
test_collection - Chunk Size:
64, Chunk Overlap:16, Top K:5 - Weaviate URL:
http://localhost:8080
- Embedding Model:
- AI Data Processing
- Generates the final answer from retrieved passages
- Data Flow Spy
- Displays the generated response
Workflow Steps
- Load input with the Data Source node using a query prompt and the attached text document.
- Index and retrieve passages with the RAG node from the
test_collectionvector store. - Generate an answer with the AI Data Processing node using the retrieved evidence.
- Inspect the final output in the Data Flow Spy node.